RESUMEN.- El propósito de este trabajo consiste en describir en primera instancia las variables de segmentación demográficas consideradas en el estudio de como las personas tienden a discriminar entre dos criterios básicos de compra: el de diferenciación de productos vs. precios. En una segunda etapa de la investigación se progresa en las pruebas de hipótesis con fundamento en Chi-cuadrado y estadísticos Wald para mostrar la significancia de estos criterios de segmentación en la explicación del criterio de compra seleccionado por el consumidor. Esta investigación se realiza en la ciudad de Culiacán, Sinaloa México a finales de 2012, a través de una de muestra de 349 compradores. Los resultados obtenidos nos muestran una relación significativa para un nivel a=0.05, para solo 2 de 8 variables; el nivel educativo y el nivel de ingresos del consumidor. Por tanto, se cuenta con una relación concluyente y estadísticamente significativa.
Palabras clave: Segmentación demográfica, Decisión de compra binaria, Estadístico de prueba de Wald.
JEL: C25, M31
ABSTRACT. - The purpose of this paper is to describe demographic segmentation variables considered in the study in the first instance of as people tend to discriminate between two basic buying criteria: that of differentiating products vs. prices. In a second stage of research progress in testing of hypotheses based on Chi-square and statistical Wald to show the significance of these segmentation criteria in the explanation of the buying criteria selected by the consumer. This research is conducted in the city of Culiacan, Sinaloa, Mexico in late 2012, through a sample of 349 buyers. The results obtained show a significant relationship to a level a = 0. 05, for only 2 of 8 variables; the educational level and the level of income of the consumer. Therefore, it boasts a conclusive and statistically significant relationship.
Key words: Demographic segmentation, binary purchase Decision, Wald test.
1.- Introducción.
El antecedente inmediato de la presente investigación se deriva directamente de la investigación precedente Diferenciación de Productos a través de Regresión Logística Múltiple. El caso de los Alimentos Básicos. Que el autor presento como requisito en la investigación para la consecución del grado de Doctor en Administración, derivando de ello una serie de ventanas de oportunidad para futuras indagaciones, siendo en esta ocasión, el planteamiento relativo a la importancia significativa de las características de segmentación en los compradores de productos básicos que optan por el requisito para la adquisición de satisfactores el criterio de diferenciación de productos en contrapartida al criterio prevalente de los precios. De esta forma se establece una liga natural con la temática tratada por el autor de la cual se retoman y trabajan algunos aspectos íntimamente relacionados.
Por consiguiente, el propósito de trabajar en el diseño de modelos para el área de negocios y estudios de mercados concentrando fuertemente la atención, particularmente en el campo de la diferenciación de productos y, las variables de segmentación en las decisiones de los consumidores como elementos concluyentes en la discriminación que se hace entre el criterio de precios contra el basado en la diferenciación de atributos en el producto, tiene correspondencia con el reto que se plantean las organizaciones de distinguirse del resto de los competidores entre empresas y productos y, en conocer las variables estratégicas en la segmentación de su mercado y, con ello lograr un posicionamiento efectivo teniendo como corolario deseable en consecuencia, un cierto grado de control monopólico sobre el precio de la mercancía que ofrece en el mercado.
De esta manera, es de trascendencia mayor la actividad de identificar, seleccionar y especificar las principales características (de los consumidores), que deben ser predichos y analizados en el proceso para la incorporación de éstos elementos en la explicación de la importancia que revisten en la toma de decisiones por parte del comprador de productos básicos.
Paralelamente, los esfuerzos y la tendencia hacia la definición del tipo de modelos a utilizar para propósitos de pronósticos y de diagnósticos comerciales direccionan hacia los prototipos multimétodos, así, según Padgett, citado por Kerlinger (2001), éstos, consisten en una mezcla de elementos cuantitativos y cualitativos en la explicación de un fenómeno de interés, por ejemplo en las áreas de la administración, economía, mercadotecnia, entre otras disciplinas sociales. Lo que motiva fuertemente la investigación a abrevar en el camino de los modelos de elección discreta.
De acuerdo a Ceniceros (2001), hasta aquí es clara la necesidad de establecer lineamientos para encauzar correctamente el esfuerzo en la consecución de estos propósitos a saber el diseño de modelos; sin embargo, esta etapa plantea los siguientes aspectos, primero; la inserción de los negocios en un ámbito de competencia internacional antes no vista, lo que traza el problema de reingeniería de procesos y la consideración de escenarios cambiantes para la instrumentación de estrategias de competitividad en los negocios, ante la vorágine de acontecimientos en el corto plazo que cambia rápidamente la posición competitiva de los países y sus mapas tecnológicos. En segundo lugar, el cambio vertiginoso en las tendencias económicas, financieras, tecnológicas, políticas, condiciona a las organizaciones comerciales a un estado de la naturaleza de incertidumbre en donde el factor información adquiere una dimensión vital.
Un ambiente de esta naturaleza dificulta el proceso de toma de decisiones en la empresa, de allí la importancia capital de trabajar arduamente en el diseño de estrategias (diferenciación de productos, segmentación, v., gr.) para lograr posicionar efectivamente a la empresa y sus productos, distinguiéndola de los competidores. Una vez, que el administrador se da cuenta de la complejidad del macro ambiente de los negocios, desecha generalmente los métodos poco robustos y, se compromete seriamente con análisis que utilizan una mayor cantidad de información y planeación de sus actividades, buscando establecer o distinguir su ventaja competitiva.
Sin duda, es manifiesta la importancia de diferenciar los productos alimenticios básicos ya que trae entre otros beneficios para la empresa, el contar con un poder de mercado y cierto control sobre el precio que cobra al consumidor, dándole cierto grado monopólico y, adicionalmente un importante posicionamiento del producto en la mente del consumidor, lo que permite a la empresa buscar en el más largo plazo la fidelidad de los clientes hacia el producto, generando de paso confianza sobre el mismo y prolongando su horizonte de vida en el mercado; situación que transfiere como consecuencia deseada un importante flujo económico en pago de remuneraciones y desde el punto de vista social, quizás lo más importante, la conservación de las plazas de trabajo, entre otros beneficios. Sin embargo, para que ello fructifique, antes es necesario segmentar o estratificar a los grupos de consumidores por lo que reviste de especial importancia el correlacionar y determinar la contribución individual de cada variable de segmentación en las personas que opten o se decidan por el criterio de la diferenciación de atributos en la toma de decisiones con relación a los productos básicos a adquirir frente a la alternativa decisoria del criterio de los precios, de allí, que en esta propuesta de investigación se busque explorar por la estrategia de elecciones discretas, a través de un modelo pues, que discrimine la variable dependiente en forma binaria (precios vs atributos).
Observemos también que, con la necesidad descrita hasta ahora, es de suma trascendencia el desarrollo de prototipos para la diferenciación de productos en base a criterios de segmentación a través de modelos de elección discreta ya que, en la disertación teórica de la mercadotecnia en este tema se ha enfatizado en aspectos propiamente generales al reconocer solo orientaciones en el tratamiento del tema de interés presentando un área de procedencia para la investigación y la práctica ante la ausencia de modelos que vengan a contribuir en forma práctica y concreta a resolver falencias en este campo de conocimiento.
2.-Estrategia Metodológica.
2.1. Enfoque de investigación.
En cuanto al tratamiento y cumplimiento de los objetivos planteados en la investigación se guiaran por el acatamiento a la metodología tradicional econométrica, concretizado a través del modelo de regresión logística Binaria (RLB), en donde en primera instancia se parte del planteamiento de la teoría y de las hipótesis, para posteriormente especificar el modelo de acuerdo a la aportación teorética, obtener la información y estimar los parámetros del prototipo econométrico.
2.2. Contexto de la investigación.
La presente investigación, se desarrolla en la ciudad de Culiacán, Sinaloa con el levantamiento de la información. La estratificación del área se realizará dividiendo la ciudad en 4 regiones (Norte, Sur, Noreste y Noroeste) abarcando prácticamente la totalidad de los centros comerciales (hipermercados), en donde los consumidores ordinariamente realizan la compra de los alimentos básicos. A continuación, se presenta la relación de hipermercados y su correspondiente número de personas encuetadas en esos sitios:
2.3. Universo y procedimiento muestral.
El universo de la presente investigación se encuentra conformado por todas aquellas personas que realizan la compra de productos básicos en la ciudad de Culiacán, no pudiéndose determinar numéricamente ya que, en algunas ocasiones se trata de hogares con solo un decisor, en otros casos con hogares de 2 o más personas que realizan las compras. Con relación al tipo y procedimiento en la determinación y selección de los participantes en la muestra tenemos lo siguiente:
Se realiza una nueva prueba piloto durante el verano del 2011, para determinar el tamaño de muestra aplicada a compradores, para contrastarla con la realizada durante los días 12 y 15 de Junio de 2008, en hipermercados de la localidad con el propósito de determinar los nuevos valores de 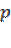 (proporción de compradores que privilegian el precio en la compra de productos básicos ) y
(proporción de compradores que privilegian el precio en la compra de productos básicos ) y 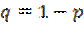 , a través del método de entrevista personal de intercepción en centros comerciales, seleccionando en forma aleatoria a cada
, a través del método de entrevista personal de intercepción en centros comerciales, seleccionando en forma aleatoria a cada 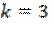 sujetos haciéndole la pregunta clave, sobre cuales es el principal criterio utilizado en la compra de aceites comestibles. Siendo las categorías de respuestas:
sujetos haciéndole la pregunta clave, sobre cuales es el principal criterio utilizado en la compra de aceites comestibles. Siendo las categorías de respuestas:
1.- Precio. 2.- Características del producto.
Finalmente, para realizar la encuesta se procederá a determinar el tamaño de muestra de la siguiente manera:
Niveles de error (ε) y confianza en la determinación del tamaño de muestra probabilística con proporciones (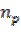 ) cuando se desconoce la población (
) cuando se desconoce la población (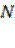 ).
).
* 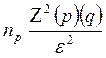
Tratándose de estimación de proporciones entre los que deciden la compra preponderantemente a través de la variable precio y los que se deciden por las características (atributos) del producto, se empleará un error de 5.0% y un nivel de confianza del 95%, así como los proporciones que se obtendrán con anterioridad en la prueba piloto, en la determinación del tamaño mínimo de muestra. Es importante recordar que en el trabajo realizado durante el año 2008 se aplicaron 310 cuestionarios. Ahora se aplicarán con los valores actualizados de p y q un total de 349 cuestionarios.
2.4. Diseño de investigación.
El presente trabajo se corresponde con un diseño de investigación de tipo no experimental en donde se relacionan y explican a través de una función de tipo discreta la variable dependiente binaria (diferenciación de producto frente a precios), por medio de covariables (segmentación), explicativas seleccionadas a través de la aportación teorética sobre segmentación de consumidores. Así mismo, se trata de un estudio de tipo transversal.
2.5 Proceso de recolección de datos.
La encuesta se realiza preferentemente en el horario de 10 a.m. a 12 p.m., seleccionando en forma aleatoria sistemática en intercepción en centro comercial a cada 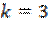 sujetos y, buscando que cada establecimiento comercial cubriese geográficamente la región seleccionada (cuadrante) y determinando el número de entrevistas a realizar.
sujetos y, buscando que cada establecimiento comercial cubriese geográficamente la región seleccionada (cuadrante) y determinando el número de entrevistas a realizar.
2.6. Procedimiento general y procesamiento de datos.
Para llegar a estimar definitivamente el modelo con fines de diagnóstico y predicción, se procede en términos generales de la forma siguiente:
_ Revisión teórica de los factores de segmentación, diferenciación y modelos de elección discreta.
_ Análisis de la información secundaria, lo que permitirá comprender de mejor manera el problema de investigación.
_ Selección del método de recogida de datos en escala métrica y no métricas a través de la técnica de la encuesta.
_ Preparación y redacción del cuestionario.
_ Diseño del plan de muestreo y determinación del tamaño de la muestra.
_ Plan para análisis de la información.
_ Estimación los parámetros del modelo seleccionado que permita entender la contribución y explicación de cada variable de segmentación seleccionado en la diferenciación del producto.
En cuanto al procesamiento y análisis los datos, se utilizará el paquete estadístico SPSS V.19.
3.- Los paradigmas de dependencia: regresión logística simple y múltiple en el estudio de la segmentación y la diferenciación de productos.
En el presente tratado consideremos una primera aproximación a los modelos para validar empíricamente el problema de la diferenciación de productos alimenticios básicos, entonces se parte de la ecuación (1) con la incorporación de un término de error estocástico (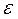 ):
):
-
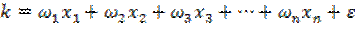 .
.
Por lo tanto, de la expresión anterior, se pueden identificar los siguientes elementos estructurales, vid., Gujarati (2010), que permitirán en lo subsiguiente ir revisando y evaluando la factibilidad de los modelos propuestos en la consecución de los objetivos planteados en la investigación:
1.) 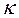 , valor teórico (variable respuesta).
, valor teórico (variable respuesta).
2.) 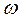 η, parámetros o coeficientes de la ecuación.
η, parámetros o coeficientes de la ecuación.
3.) 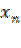 , variables independientes.
, variables independientes.
4.) 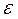 , residual o término de error estocástico.
, residual o término de error estocástico.
Analicemos, pues, el modelo de Regresión Logística (RL), a la luz de su estructura funcional. Primero, con relación a los valores 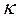 , tenemos que para Hair, Anderson, Tatham y Black (1999), en una primera versión de este modelo la consideran como una variable dicotómica (binaria),es decir, se refieren a una variable respuesta de dos grupos, a diferencia de la Regresión Múltiple, (RM) que predicen las probabilidades de ocurrencia del fenómeno a analizar. Por lo que los valores respuesta se encuentran acotados entre los valores 0 y 1.
, tenemos que para Hair, Anderson, Tatham y Black (1999), en una primera versión de este modelo la consideran como una variable dicotómica (binaria),es decir, se refieren a una variable respuesta de dos grupos, a diferencia de la Regresión Múltiple, (RM) que predicen las probabilidades de ocurrencia del fenómeno a analizar. Por lo que los valores respuesta se encuentran acotados entre los valores 0 y 1.
Especificando, la parte generalizada funcional de 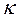 , en su forma operativa, según Gujarati (2010), tenemos que:
, en su forma operativa, según Gujarati (2010), tenemos que:
Si 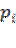 = probabilidad de éxito de un evento determinado.
= probabilidad de éxito de un evento determinado.
Una forma de modelar un problema con variable dependiente dicótoma, puede ser:
(2) 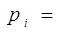
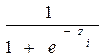 Función de Distribución Logística.
Función de Distribución Logística.
Donde 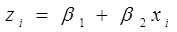
 La probabilidad de no ocurrencia del evento, se puede establecer como:
La probabilidad de no ocurrencia del evento, se puede establecer como:
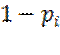 =
= 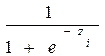
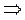 La variable respuesta puede quedar expresada como la siguiente razón de probabilidades (odds ratio):
La variable respuesta puede quedar expresada como la siguiente razón de probabilidades (odds ratio): 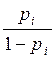 =
= 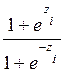
Ahora bien, este modelo también puede ser presentado de la siguiente manera en relación a su variable respuesta, así para Pyndyck y Rubinfeld (2001), el modelo se basa en la siguiente expresión de probabilidad logística acumulativa:
(3) 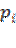
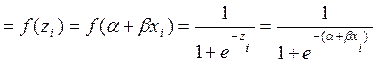
Donde 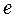 , base de logaritmos naturales
, base de logaritmos naturales 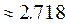 , el autor retoma (3) y multiplica ambos lados de la ecuación por
, el autor retoma (3) y multiplica ambos lados de la ecuación por 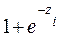 y se obtiene (
y se obtiene (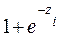 )
) =1, para luego dividirlo entre
=1, para luego dividirlo entre 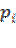 y restándole 1, tenemos:
y restándole 1, tenemos: 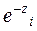 =
=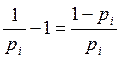 , como
, como 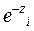 =
= 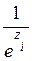
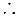
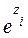 =
=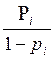 aplicando el logaritmo natural en ambos lados, tenemos que:
aplicando el logaritmo natural en ambos lados, tenemos que:
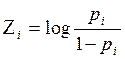
Por tanto, retomando (3), finalmente se puede expresar la variable respuesta como:
(4) 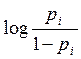 =
=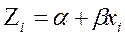
Autores clásicos en la Regresión Logística son Hosmer y Lemeshow (1989), que en su trabajo clásico Applied Logistic Regresión, razonan de la siguiente manera en relación al valor esperado de la variable respuesta en una función lineal como:
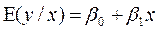
De donde se establece que  se mueve en rangos de
se mueve en rangos de 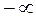 y
y 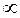 . Pero con variables de respuesta de tipo dicotómica los rangos se establecen en
. Pero con variables de respuesta de tipo dicotómica los rangos se establecen en 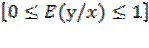 Si,
Si, 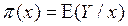 , Por lo tanto el modelo Logístico se especifica como:
, Por lo tanto el modelo Logístico se especifica como:
(5) 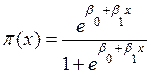
Finalmente, efectúan una transformación logística definiéndola en términos de: 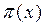 , así, (6)
, así, (6)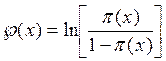
 =
= 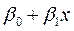
Para seguir a Ferrán (2001), digamos que: 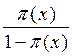 =
= 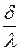 y
y 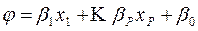 , entonces:
, entonces: 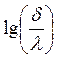 =
= 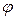
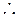 una forma adicional de presentar el modelo es:
una forma adicional de presentar el modelo es:
(7) 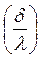 =
= 
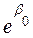 (
(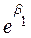 )
)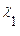 ….(
….(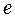
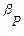 )
)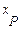
Segundo, con relación a 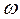 η, parámetros o coeficientes de la ecuación (en términos generales), se tiene que para Gujarati (2000), esos parámetros quedan expresados en términos de las siguientes literales:
η, parámetros o coeficientes de la ecuación (en términos generales), se tiene que para Gujarati (2000), esos parámetros quedan expresados en términos de las siguientes literales: 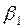 y
y 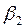 , así tenemos que, si:
, así tenemos que, si: 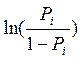 =
= 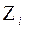 ,
, 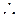 linealizando la expresión,
linealizando la expresión, 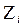 =
= 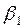 y
y 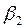
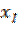 , ahora bien, ¿qué interpretación hace el autor de estos coeficientes o parámetros?. En el contexto de un problema que relaciona los niveles de ingreso con las probabilidades de adquirir una casa, Gujarati (2010), comenta:
, ahora bien, ¿qué interpretación hace el autor de estos coeficientes o parámetros?. En el contexto de un problema que relaciona los niveles de ingreso con las probabilidades de adquirir una casa, Gujarati (2010), comenta:
La interpretación del modelo logit es la siguiente: 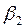 , es la pendiente, mide el cambio en ℓ ocasionado por un cambio unitario en
, es la pendiente, mide el cambio en ℓ ocasionado por un cambio unitario en  , es decir, dice cómo el logaritmo de las probabilidades a favor de poseer una casa cambia a medida que el ingreso cambia en una unidad, por ejemplo US $ 1000. El intercepto
, es decir, dice cómo el logaritmo de las probabilidades a favor de poseer una casa cambia a medida que el ingreso cambia en una unidad, por ejemplo US $ 1000. El intercepto 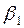 es el valor del logaritmo de las probabilidades a favor de poseer una casa si el ingreso es cero. (P.544).
es el valor del logaritmo de las probabilidades a favor de poseer una casa si el ingreso es cero. (P.544).
Por lo que es necesario, volver a transformarlos al aplicarles el anti log, los signos de los coeficientes, entonces se interpretarían de la siguiente manera:
(8) 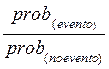 =
= 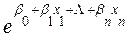
Complementando lo anterior, de acuerdo a Álvarez (1995), con respecto al significado de los coeficientes en la explicación o contribución de la variable de respuesta binaria tenemos que:
El signo de los coeficientes tiene un significado importante. Si los coeficientes de las variables son positivos, eso significa que la variable aumenta la probabilidad del suceso que estamos estudiando. Si este fuera una enfermedad, el factor cuyo coeficiente es positivo aumentaría la probabilidad de padecer la enfermedad y, por lo tanto, dicho factor sería un factor de riesgo. Si el coeficiente es negativo, el factor cuyo coeficiente es negativo disminuye la probabilidad del suceso que estamos estudiando; en caso de que dicho suceso fuera una enfermedad, estaríamos ante un factor de protección. (P.158).
Tercero, en lo que se refiere a las variables independientes o explicativas en el modelo (RLS), un modelo simple solo incluye una variable explicativa, pudiendo representarse de la siguiente manera:
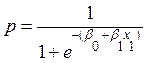 , pero así mismo, un modelo se pude especificar como un modelo múltiple de la siguiente forma: (9)
, pero así mismo, un modelo se pude especificar como un modelo múltiple de la siguiente forma: (9) 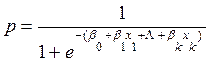 ,
,
Es importante destacar que las variables explicativas pueden ser tanto cuantitativas como cualitativas. En el caso de las cualitativas es necesario convertirlas en dummy. Ésta es una variable cualitativa, siempre y cuando tengan la propiedad de de ser codificadas en forma numérica con la regla conocida de que si se tienen 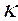 , numero de categorías, entonces habrá que crear
, numero de categorías, entonces habrá que crear 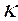 -1 variables dummy. Álvarez (1995).
-1 variables dummy. Álvarez (1995).
Pasemos al examen, ¿Qué sucede cuando en un modelo RL, se tienen más de una variable explicativa? Para Álvarez (1995), es necesario comprobar si existe efecto interacción entre las variables consideradas en el modelo, de tal forma que si retomamos la ecuación (9) y la simplificamos, obtenemos la ecuación (10): (10) 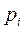 =
=
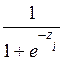 , el exponente puede tener incluidos varias
, el exponente puede tener incluidos varias 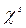 , por ejemplo si:
, por ejemplo si:
(11)
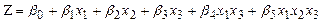
Entonces, se habla de un modelo con interacción binaria (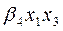 ) en la primer parte y de una interacción terciaria (
) en la primer parte y de una interacción terciaria (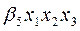 ), en la última parte. Para obtener al final un modelo de regresión logística múltiple (RLM).
), en la última parte. Para obtener al final un modelo de regresión logística múltiple (RLM).
Cuarto, como parte estructural del modelo tenemos el término de error, residuales o perturbación aleatoria (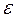 ). Así, Pyndyck y Rubinfeld (2001) relacionan la probabilidad de éxito con las variables explicativas, suponiendo que la media del residual es cero. Luego, púes:
). Así, Pyndyck y Rubinfeld (2001) relacionan la probabilidad de éxito con las variables explicativas, suponiendo que la media del residual es cero. Luego, púes:
E (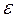 i)= (1-
i)= (1-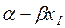 )
)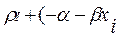 ) (1-
) (1-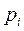 )= 0 , por lo que en términos de
)= 0 , por lo que en términos de 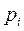 =
= 
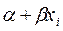 ,
,
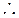
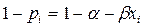
Otra forma de formular lo anterior lo tenemos en Hosmer y Lemeshow (1989), cuando fija el valor de salida como: 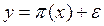 , donde
, donde 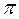 , es la probabilidad de éxito del evento considerado,
, es la probabilidad de éxito del evento considerado, 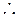 si
si 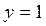 , entonces,
, entonces, 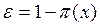 con probabilidad
con probabilidad 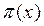 y el caso complementario, si
y el caso complementario, si 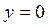 , entonces
, entonces 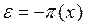 , con probabilidad 1-
, con probabilidad 1- 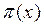 , por lo que el residual se distribuye de acuerdo a ~ (0,
, por lo que el residual se distribuye de acuerdo a ~ (0, 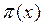 [1-
[1-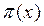 ] )
] )
En donde la media de una distribución binomial, se obtiene de 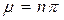 , en cambio la varianza, se obtiene de
, en cambio la varianza, se obtiene de 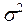 =
= 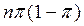 . Según Lind, Marchal y Wathen (2005).
. Según Lind, Marchal y Wathen (2005).
Para concluir, Gujarati (2010), plantea que la distribución del error (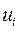 ), cuando el número de casos es elevado (N), sigue una distribución normal (
), cuando el número de casos es elevado (N), sigue una distribución normal (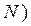 como:
como:
(12) 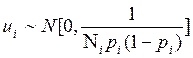
4.- Segmentación Demográfica.
En este apartado es importante destacar en este bloque un total de 8 variables dentro de la base o factores de segmentación demográfica. Estas son; Genero, edad, número de personas que contribuyen en el gasto familiar, número de habitantes por hogar, educación, ocupación, estado civil e ingreso mensual. De la misma forma importante es, prevenir sobre la dificultad en la presentación de la información en forma desplegada por la gran cantidad de categorías de respuesta en total. En este sentido se procederá a relacionar aquellas variables con fuerte implicancia teórico mercadológica y, con nivel de medición categórica en función de la variable dependiente. Para ello, cada una de las variables independientes sucesivas (covariables) por si solas (manteniendo constantes las demás), se someterán a la prueba de hipótesis nula inicial de que no se encuentra significativamente relacionada con la variable dependiente. Esto con el propósito de ir detectando en primera instancia aquellas variables que son sospechosas de ser buenas candidatas en la conformación del modelo y, por otro lado que haga posible detectar dentro del bloque estudiado el peso especifico de cada variable de segmentación. Para comprender mejor el proceso enseguida se procederá a realizar la corrida con aquellas variables candidatas a ser incluidas en el modelo.
4.1 Cruce de variables categóricas: Criterio de selección (compra) y género del comprador.
Evidentemente como ya se ha señalado por cada 7 compradores del sexo femenino 3 se corresponden con el género masculino y, en cuanto a la preferencia total en el criterio de compra se puede concluir que los porcentajes sin parecidos pero en el sentido de que del total de los entrevistados el 67% aproximadamente prefieren el criterio de compra basado en la diferenciación. Sin embargo, si analizamos la información de la tabla 6, dentro de los grupos observaremos que por ejemplo en el caso de las féminas que el 22.1% prefiere el criterio de los precios contra el 46.7% que opta por la diferenciación. En cambio en el caso de los hombres se corresponde a 10.6% y 20.6% respectivamente.
¿Es suficiente la evidencia presentada para aseverar que se relacionan significativamente ambas variables? Pasamos al análisis para probar la hipótesis de no relacionamiento ya comentadas.
Efectivamente el género no se encuentra significativamente relacionado con el criterio de compra.
Sin embargo, aún cabe la duda razonada de que esa muestra en particular allá arrojado esos resultados producto todavía del azar. Existe una herramienta muy poderosa (bootstraping) para generar en un instante un reemuestreo a través de poderoso software que hace más robustos los resultados y genera intervalos de confianza que nos ayuden a aumentar la fiabilidad de la prueba de hipótesis de significancia asimismo de los coeficientes estimados. Hair, Anderson y Tatham (2001). En lo sucesivo cuando una de las pruebas de significancia estadística se considere central en el desarrollo y análisis de la información, se señalara que se someterán a la estrategia del reemuestreo bootstrap definiendo para ello un nivel de confianza del 95% con muestreo simple con un total de 1,000 muestras.
5.- CrossTab y Prueba de significancia: Edad vs. Criterio de decisión.
Por lo que respecta a la caracterización y estructura de la información relativa a los rangos de edad de los consumidores, podemos destacar que, en la captura de la información se cuenta con un total de 340 sujetos y 11 casos perdidos. Cfr.
De ese total tenemos la presencia de la categoría de edad balanceada en el sentido de que se encuentra constituida por estratos que se describen a continuación: compradores en la categoría de 18-28 años 22.6%, compradores en el rango de 29-39 años de edad 28.5%, la siguiente categoría de respuesta lo constituyen quienes declararon en el rango de 40- 50 años con un 28.8%.Siendo los anteriores categorías las más representativas de la población. En términos marginales se cuenta con los rangos entre 51-61 años con el 13.2% y, quienes declararon tener más de 61 años con el 6.8%. Tengamos en cuenta que más de la mitad corresponden a individuos que declararon contar con una edad entre los 18 y 39 años lo que habla evidentemente de una conformación poblacional todavía joven en la ciudad.
Tome en cuenta que en términos de la muestra, los rangos de edad en donde en mayor medida se opta por el criterio de la diferenciación del producto es el que va de 40-50 años con un 18.5% del total de toda la muestra que prefiere utilizar ese criterio de compra.
¿Están relacionados significativamente las variables edad del comprador y el criterio de selección de compra en la población? Veamos. Como se puede apreciar en la tabla siguiente el valor del estadístico Cui-cuadrado es de 3.309 y al verificar su significancia vemos que es superior al α .05. Por lo que no se rechaza la hipótesis nula. Esto es, no existe suficiente evidencia empírica para suponer que en la población exista una relación entre el criterio de compra utilizado y la edad del comprador.
6.- La variable nivel educativo de los compradores.
Pasemos al examen ahora en la forma como se relacionan el nivel educativo de los respondientes con el criterio utilizado en la compra de aceites comestibles. Para tal propósito, la variable de interés se ha categorizado en seis opciones que van desde primaria inconclusa hasta el nivel máximo de posgrado.
De la información anterior queda claro que a niveles superiores de estudio (licenciatura y posgrado), la tendencia favorece claramente al criterio de compra basado en la comparación y valoración de los atributos de los productos. Generalmente, a mayor nivel de estudios mayor ingreso percibido y por supuesto en esos niveles de estudios se busca mayor reconocimiento social. Hay un claro aprendizaje de los esfuerzos por parte de la publicidad por diferenciar y posicionar el producto hacia ciertos segmentos del mercado. Solo pensemos en dos posibles conectores con el nivel educativo de las personas y, por ende en su criterio de compra.
Factores importantes son, primero, el relativo a la discriminación de estímulos relacionado con el aprendizaje del comportamiento del consumidor, definido como la capacidad del individuo para percibir diferencias importantes en los estímulos. Segundo, la clase social siendo esta la misma se comparten actitudes, estilos de vida y comportamiento de compras similares. Kerin, Hartley y Redelius (2009).
Por la argumentación anterior, es al parecer interesante recategorizar las variables de suerte tal que, reconfiguremos un cluster constituido por aquellas personas que solo tienen como nivel de estudios hasta la secundaria y, otro conformado por aquello que van desde el nivel preparatoria hasta posgrado. Para aclarar esta propuesta, consideremos la información siguiente (recategorizada).
Observemos como de seis categorías se han reducido a tres bajo la nueva etiqueta Edu_rec: Educación básica, preparatoria y, por último educación profesional. Con lo que se ha alcanzado un balance representativo en cuanto al tamaño de los nuevos segmentos con fuerte significación social y profesional. Ahora, formalicemos la prueba de significancia a través de plantear la siguiente hipótesis.
H0 : “La variable nivel educativo de los compradores no tiene relación con el criterio de compra utilizado bien sea este el precio o la diferenciación por atributos.”
Como se comprueba, el ensayo resulta ser altamente significativo. Por lo que se rechaza la hipótesis nula y con ello procedemos a seleccionar a tan importante variable de segmentación demográfica en la configuración del modelo de regresión logística, ingresando ahora en la modalidad de covariable. ¿Es esta candidata una variable apropiada en el modelo? Pasemos a analizar esta situación.
6.1.- Prueba de Hipótesis con estadístico Wald y procedimiento bootstrap para el nivel educativo.
Antes de probar la hipótesis de significancia individual de la variable nivel educativo, procedemos a la codificación de la misma. .
Como se puede deducir de la tabla anterior, la categoría educación básica es la categoría de referencia o comparación. ¿Por qué se selecciono esa categoría como referente?
Por qué lo que queremos indagar es el papel de la educación en el criterio de discriminación y, se parte de suponer que quienes tienen mayor nivel de educación tienden hacia la discriminación por atributos en el criterio de compra. En cambio al nivel de estudios de preparatoria se le asigna la categoría (1). Finalmente a nivel profesional el código (2).
Ahora bien, ¿Es el coeficiente que acompaña a la covariable nivel de estudios igual a cero en la población? Dicho de otra manera, ¿se encuentran relacionadas significativamente las variables dependiente e independiente? Expresemos formalmente la hipótesis nula.
H0 : “La variable educación no se encuentra asociada en la explicación en la forma en cómo los consumidores deciden utilizar el criterio de compra binario.”
Para contar con mayores elementos de fiabilidad y potenciar la veracidad de los resultados se realiza la prueba de hipótesis utilizando el procedimiento bootstraping con un total de 1,000 muestras. Los resultados se presentan a continuación.
De la tabla anterior se deduce la alta significancia de la variable educación en la discriminación en el criterio de compra del consumidor y alternativamente el procedimiento bootstrap nos permite construir intervalos de confianza al 95% para probar la H0 de independencia entre la covariable y la variable dependiente. Si observa con atención podrá notar que los coeficientes par las variables Educareca (1) y Educareca (2), caen dentro de los intervalos de confianza respectivos, por lo que de igual manera se rechaza la H0 llegando a la misma conclusión. Por lo que habremos de retomar más adelante tan significativa covariable en la construcción del modelo de elección discreta.
6.2.- La ocupación del comprador como covariable candidata en el modelo de elección discreta.
Cuando analizamos la variable ocupacional de los compradores entrevistados encontramos que no es una candidata significativa a ingresar al modelo ya que, como se puede apreciar en la tabla 47, el valor calculado del estadístico (8.723) no es significativo dado que el valor teórico o crítico es de 12.592 (extraído de tablas), para 6 grados de libertad, es decir (r-1) (c-1).
Adicionalmente, hay que hacer notar que como parte de la restricción en el uso de la técnica de tabulación cruzada tenemos 2 casillas con frecuencias esperadas menor a 5, lo cual se constituye en un problema estructural en la prueba. Cierto es, que se pudiesen compactar las categorías de respuesta siempre y cuando tuviesen una consideración teórico-práctica lo cual no es el caso, dada la diversidad de categorías de respuesta utilizados en las esta variable. Dada la contundencia de la prueba estadística utilizando procedimiento bootstrap, la variable se descarta.
6.3.- La variable estado civil de los compradores en el criterio de compra.
Por lo que respecta a la posible correlación entre la variable estado civil de los respondientes y el criterio binario de compra los resultados son:
Aún y cuando se compacten las categorías de respuesta a casados que representan el 61.1% de la muestra y el resto de las categorías los resultados seguirán siendo no significativos.
Por tanto al realizar la corrida correspondiente a la tabla 20, se puede concluir sobre la independencia de las variables.
6.4. - Prueba de hipótesis de independencia entre las variables nivel de ingreso y criterio de compra.
Para analizar la significancia o no de esta variable estratégica desde la teoría económica y mercadológica dentro del bloque de segmentación demográfica, procedemos a la utilización de la técnica bootstrap.
Como podemos apreciar en la tabla siguiente la prueba estadística resulta altamente significativa con un valor calculado Chi-cuadrado de Pearson de 20.161 con un valor de probabilidad bajísimo (.000).
Para mayor información se incorpora en la figura 8, el valor teórico para 3 grados de libertad y nivel de significancia α = 0.05.
En suma, contamos ahora con nuestra segunda variable dentro del bloque de segmentación demográfica a incorporar al modelo propuesto. Por lo que ahora le conoceremos en el ambiente de la regresión logística como covariable (explicativa).
6.5.- Variables métricas en la segmentación demográfica: Número de personas que contribuyen al gasto familiar y número de habitantes por hogar.
Una variable importante a considerar de acuerdo a la aportación teórica es sin duda el número de personas que contribuyen con el gasto familiar en el hogar. Hay que recordar que dicha variable tiene en principio un nivel de medición de tipo métrico. También es pertinente aclarar que del total de los 351 encuestados por lo referente a esta medición se cuenta con la ausencia de respuesta de tan solo 10 casos por o que el tamaño de la muestra sigue siendo representativo.
En cuanto a la importancia relativa de esta variable métrica encontramos que efectivamente ésta no es significativa a un nivel de significancia del 5%. Por tanto, se procede a no rechazar la hipótesis nula y, con ello concluimos que midiendo en forma métrica esta variable se descarta para posterior análisis. Note en el círculo en rojo el valor asociado al estadístico Wald (.524) y su correspondiente significancia (.469).
Aún y cuando se intenta recategorizar para formar cluster más consistentes tenemos la misma decisión de rechazar la H0. A continuación se presentan los detalles.
Solo hay que puntualizar sobre el hecho de la recategorización en la nueva variable Contrica que queda reducida a tres categorías consistentes en; una persona contribuye con los gastos del hogar, dos personas y la última categoría más de dos personas.
Por lo que respecta a la variable número de habitantes por hogar se tiene que al realizar la corrida correspondiente a la estimación del modelo de regresión logística simple encontramos los siguientes resultados.
Para un total de 340 casos validos computados los resultados de significancia individual medidos a través del estadístico de Wald son igualmente no relevantes como se muestra en la tabla siguiente.
Si intentamos recategorizar y reducir el número de segmentos, los resultados no cambian e incluso aún ni reduciendo a dos categorías de respuesta, siendo estas de 1 a 4 habitantes y más de 4 habitantes. Por tanto, el número de habitantes por hogar no es factor de discriminación contrario a lo que el “sentido común” pudiese indicar.
Referencias Bibliográficas.
- Álvarez, R. (1995). Estadística Multivariante y no Paramétrica con SPSS. Aplicación a las Ciencias de la Salud. España: Díaz de Santos.
- Ceniceros, J. (2001). Modelo de Pronostico de Exportación de Calabaza Kabocha al Mercado Japonés. Tesis de maestría no publicada, Universidad de Occidente, Culiacán, Sinaloa, México.
- Gujarati, D. (2010). Econometría. (5ra Edición). Mexico: Mc Graw Hill.
- Hair, J., Anderson, R., Tatham, R. y Black, W. (1999). Análisis Multivariante. (5ta Edición). España: Prentice Hall Iberia.
- Hosmer, D. y Lemeshow, S. (1989). Applied Logistic Regression. United States of America: Wiley Interscience Publication.
- Kerin, R., Berkowitz, E., Hartley, S. y Redelius W. (2009). Marketing. México: Mc Graw Hill.
- Kerlinger, F. (2001). Enfoque Conceptual de la Investigación del Comportamiento. México: Interamericana.
- Lind, D., Marchal, W., y Wathen, S. (2005). Estadística Aplicada a los Negocios y a la Economía. (12 edición). México: Mc Graw Hill.
- Pindyck, R. y Rubeinfeld, D. (2001). Econometría: Modelos y Pronósticos. (4ta Edición). México: Mac Graw Hill.